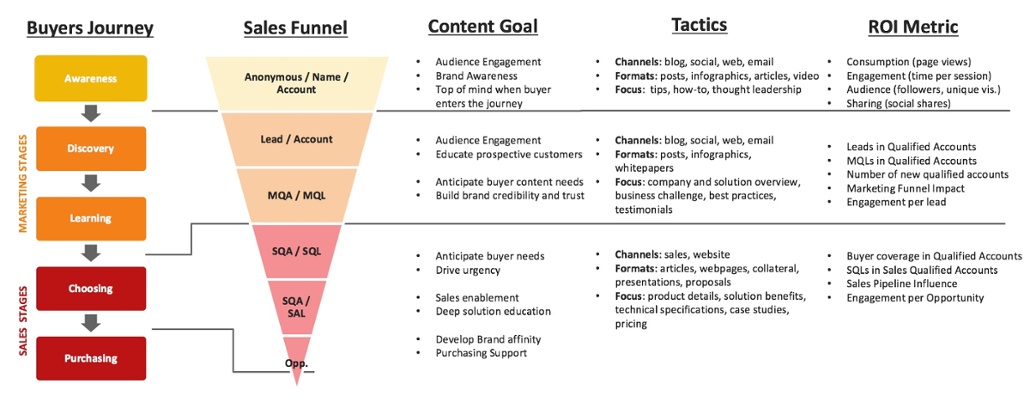
Oggi ho chiesto a Bing quali sono i principali 20 fattori di valutazione dell’affidabilità di una fonte citata da BingAI.
L’autorevolezza dell’autore o dell’organizzazione che ha pubblicato le informazioni
Questo può essere valutato considerando diversi fattori, come la reputazione dell’autore o dell’organizzazione nel loro campo di competenza, la loro esperienza e le loro qualifiche, la presenza di pubblicazioni precedenti su argomenti simili e il riconoscimento da parte di altri esperti del settore. Inoltre, possono essere presi in considerazione eventuali premi o riconoscimenti ricevuti dall’autore o dall’organizzazione per il loro lavoro.
La precisione e l’attendibilità delle informazioni presentate
La trasparenza e l’obiettività nella presentazione delle informazioni
Questo può essere valutato considerando diversi fattori, come la chiarezza e la completezza delle informazioni presentate, la presenza di fonti e riferimenti per le informazioni presentate, l’equilibrio nella presentazione di diverse prospettive e opinioni e la trasparenza riguardo a eventuali conflitti di interesse o influenze esterne. Inoltre, può essere utile confrontare le informazioni presentate dalla fonte con altre fonti affidabili per verificare la loro accuratezza e obiettività.
La data di pubblicazione per garantire che le informazioni siano aggiornate
La presenza di riferimenti a fonti affidabili
La reputazione della fonte tra gli esperti del settore
La qualità della scrittura e della presentazione delle informazioni
La completezza e la profondità delle informazioni presentate
La coerenza delle informazioni con altre fonti affidabili
L’imparzialità e l’equilibrio nella presentazione delle diverse prospettive
La presenza di revisioni indipendenti o verifiche da parte di terze parti
Questo può essere valutato verificando se la fonte fornisce informazioni su eventuali revisioni o verifiche effettuate da organizzazioni indipendenti o esperti del settore. Ad esempio, alcune fonti possono fornire informazioni su eventuali premi o riconoscimenti ricevuti da organizzazioni indipendenti per l’accuratezza o l’affidabilità delle loro informazioni. Inoltre, possono essere presi in considerazione eventuali commenti o recensioni da parte di esperti del settore che confermano l’affidabilità delle informazioni presentate dalla fonte.
L’accessibilità e la facilità d’uso della fonte per gli utenti
La presenza di meccanismi per correggere eventuali errori o imprecisioni
La chiarezza e la trasparenza riguardo alla fonte delle informazioni
L’affidabilità tecnica e la sicurezza del sito web o della piattaforma che ospita le informazioni
La presenza di politiche editoriali chiare e trasparenti
L’impegno a fornire informazioni accurate e aggiornate
La presenza di un codice etico o di condotta per garantire l’integrità delle informazioni
L’indipendenza editoriale dalla pubblicità o da altre influenze esterne
La trasparenza riguardo ai finanziamenti o alle fonti di sostegno.
E cosa mi dici dei metadati tipo schema.org?
come motore di ricerca di Microsoft, utilizzo i metadati presenti nelle pagine web, tra cui quelli forniti da schema.org. Questi metadati aiutano a comprendere meglio il contenuto delle pagine web e a fornire risposte più accurate e pertinenti alle ricerche degli utenti.
A quanto risponde, i metadati non verranno usati per dare priorità, ma solo per “approfondire”. Poi però chiedendo i dettagli del punto 1 è evidente che certe informazioni non possono stare semplicemente in pagina, ma avranno bisogno di relazioni dimostrabili.








{kind=link}