Che i commenti facciano SEO lo sappiamo da tempo, ma ora la novità (che sembra essere qui per restare) è rappresentata dalla discesa in campo di colossi del calibro di ENI che si mettono a litigare nel tribunale sociale di Facebook, per un pugno di likes… e proprio accanto ai bulli di periferia che scrivono in maiuscolo per darsi un tono.
Bounce Back e SEO: la guida DEFINITIVA
il bounce back è come il colesterolo. c’è quello buono, e quello cattivo… e spesso li si confonde.
Partiamo da ciò che misura analytics: entrambi, cumulandoli in un’unica metrica. Per analytics infatti una sessione con bounce 100% è una sessione costitutita da una sola pagina vista. Quindi se abbiamo due utenti, uno che visita una pagina e l’altro che ne visita due, la media dei loro bounce è 50%. Facile vero?
aspetta un attimo!
Che succede quando abbiamo un articolo lunghissimo ed un utente lo legge tutto senza cliccare su altre pagine? Fa bounce! Per questo motivo nei siti in cui si hanno molti contenuti sulla stessa pagina il bounce back mediamente sarà più alto rispetto che sui siti nei quali è necessario cliccare su vari link per leggere più contenuto.
Quindi devo spezzettare i miei articoli?
Guarda: questi sono i dati di un sito che coraggiosamente ha provato a implementare sia la paginazione, ed in seguito AMP, che mi da la possibilità di tracciare sia le performance che le vendite di ogni versione del contenuto (che è lo stesso in tutte le versioni, compreso il meta title è identico anche nella seconda pagina (rel=”next”)
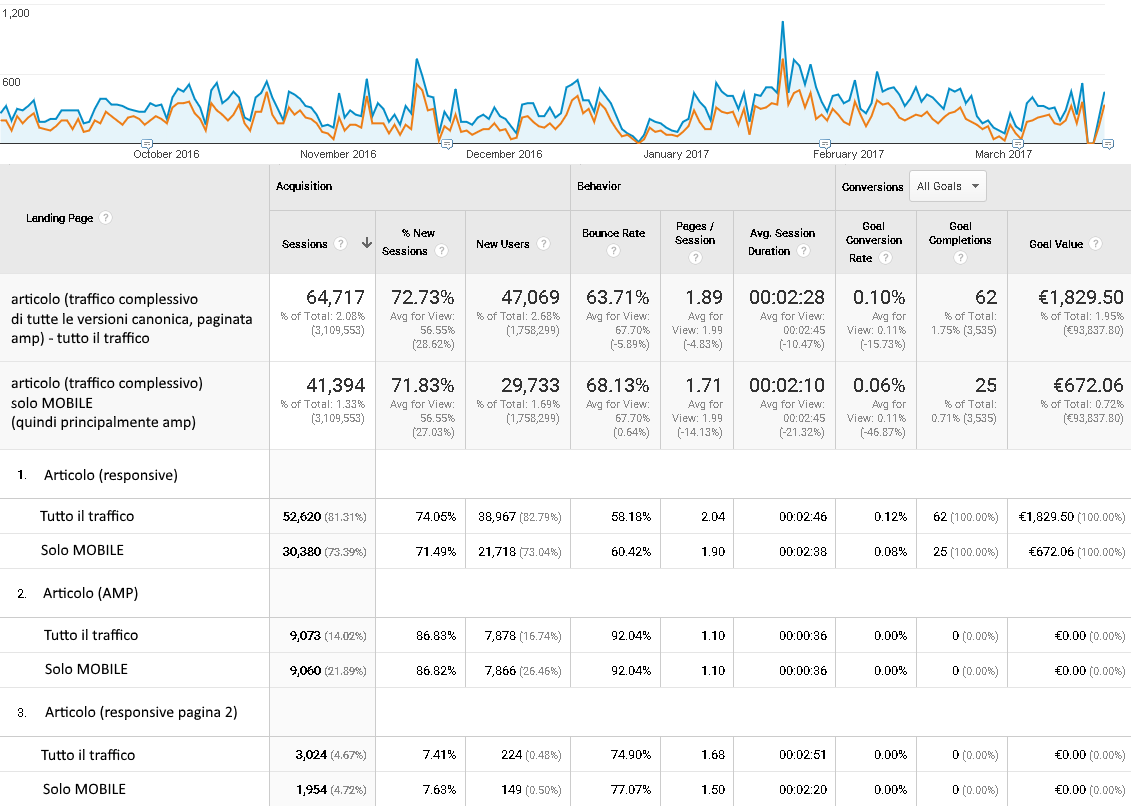
Non si è abbassato il bouce, non è migliorato il tempo di permanenza sul sito, non sono migliorate le vendite. Guardati almeno 5 minuti questi numerini e trai le tue conclusioni! Non farò cerchietti per indicare nulla.
Quindi devo fare solo articoli kilometrici?
Stiamo calmi! come al solito la risposta giusta è… DIPENDE. Partiamo un attimo dai tuoi obiettivi: il bounce back è un numero cattivo, più è basso meglio è: vero? Non è detto. Andiamo a suddividere il bounce nei suoi due tipi principali:
Bounce back esterno (il colesterolo cattivo)
- Un utente naviga una sola pagina del tuo sito e poi fa “back” per tornare a Google.
Se clicca anche sul risultato della concorrenza si chiama Pogo Sticking ed è uno sei segnali più brutti che il tuo sito possa lanciare al motore di ricerca.
Bounce back interno (il colesterolo buono)
- Un utente naviga una sola pagina del tuo sito e poi chiude il browser, totalmente soddisfatto della lettura.
Questi due scenari (interno o esterno) sono misurati da analytics nello stesso identico modo: bounce 100%. Eppure la realtà delle due situazioni è diametralmente opposta. Nel primo caso esterno probabilmente l’utente tornerà a Google ed effettuerà una nuova ricerca, questa situazione è da evitare come la peste, perchè è il classico caso che potrebbe portare a calo di posizioni organiche.
Nel caso interno invece Google non ha possibilità di misurare il feedback dell’utente, perchè dal punto di vista del motore di ricerca infatti il nostro utente non è tornato sui suoi passi (avendo chiuso il browser, o il tab del browser). Noi invece possiamo fare supposizioni. Per esempio se il nostro sito ha molti visitatori di ritorno, contenuti molto lunghi, pubblicazione puntuale di contenuti stabile nel tempo (Es. media di 4 articoli al mese per almeno un anno) allora possiamo preoccuparci poco del bounce back e cercare di capire se con l’aumentare del tempo il nostro numero unico di visitatori di ritorno tende ad aumentare. In questo caso fortuito, stiamo lavorando bene! Indipendentemente dal bounce alto.
Modi per diminuire il bounce cattivo (esterno) e non quello buono (interno)
Mettendo i link interni alle stesse ancore interne (es. come fa Wikipedia) Analytics non ha possibilità di misurare altre pageview (amenochè non si faccia il barbatrucco per lanciare almeno un evento), con questi menu interni si abbassa la probabilità che un utente non trovando subito qualcosa di suo gradimento possa fare back col browser. Io consiglio comunque di mettere sempre anche qualche link ad altri articoli, in modo da abbassare anche il bounce back generico, soprattutto su approfondimenti o temi lontanissimi (c’è sempre una percentuale di lettori pigri che non hanno voglia di finire di leggere il nostro articolo e che tuttavia si fanno attrarre da una ancora fantasiosa).
Adjusted Bounce Rate
Per lanciare un evento dopo 20 secondi di navigazione (ottenendo una frequenza di rimbalzo un pochino più utile di quella standard) aggiungere al codice di Analytics universal la riga in grassetto:
<script> (function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){ (i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o), m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m) })(window,document,'script','https://www.google-analytics.com/analytics.js','ga'); ga('create', 'UA-XXXXX-Y', 'auto'); ga('send', 'pageview'); setTimeout("ga('send', 'event', 'feedback', 'utente_interessato')",20000); </script>
e i link esterni?
Anche i link esterni nei normali post di un blog tendono ad abbassare il bounce esterno (quindi ci fanno bene… ma sul lungo periodo). Il problema coi link esterni è che sono come una scommessa nella bontà altrui: scommessa rischiosa. Se mettiamo infatti link esterni di grande qualità, perdiamo l’attenzione del lettore nel breve periodo, e speriamo di mantenere la sua attenzione sul lungo periodo (ottimo per esempio per tutti i siti che fanno della vendita dei contenuti il loro business model, pessimo per tutti quelli che monetizzano a pageview/impression).
Google conosce il bounce back del mio sito?
i dati di analytics sono le tracce sulla sabbia che hanno lasciato persone che sono già andate via: analytics è lo strumento che usiamo per fare ipotesi su dove potrebbero essere andare quelle persone, quante erano, e ci da informazioni tipo “qual’è la grandezza media dei loro piedi”.
Queste informazioni possiamo usarle per strutturare meglio il nostro sito internet, se guardando le traccie scopriamo che gli utenti che hanno il 44 di piede non entrano mai da una certa porta, possiamo fare ipotesi (forse non è abbastanza grande per loro).
COMUNQUE: analytics è un nostro strumento, che mostra un punto di vista sui dati dei visitatori del nostro sito.
Google ha la sua piattaforma di statistiche, che probabilmente è diversa da Analytics. Google giura di non guardare questi triliardi di dati di cui dispone.
Questa è un’ipotesi su ciò che potrebbe dedurre Google da un bounce back cattivo:
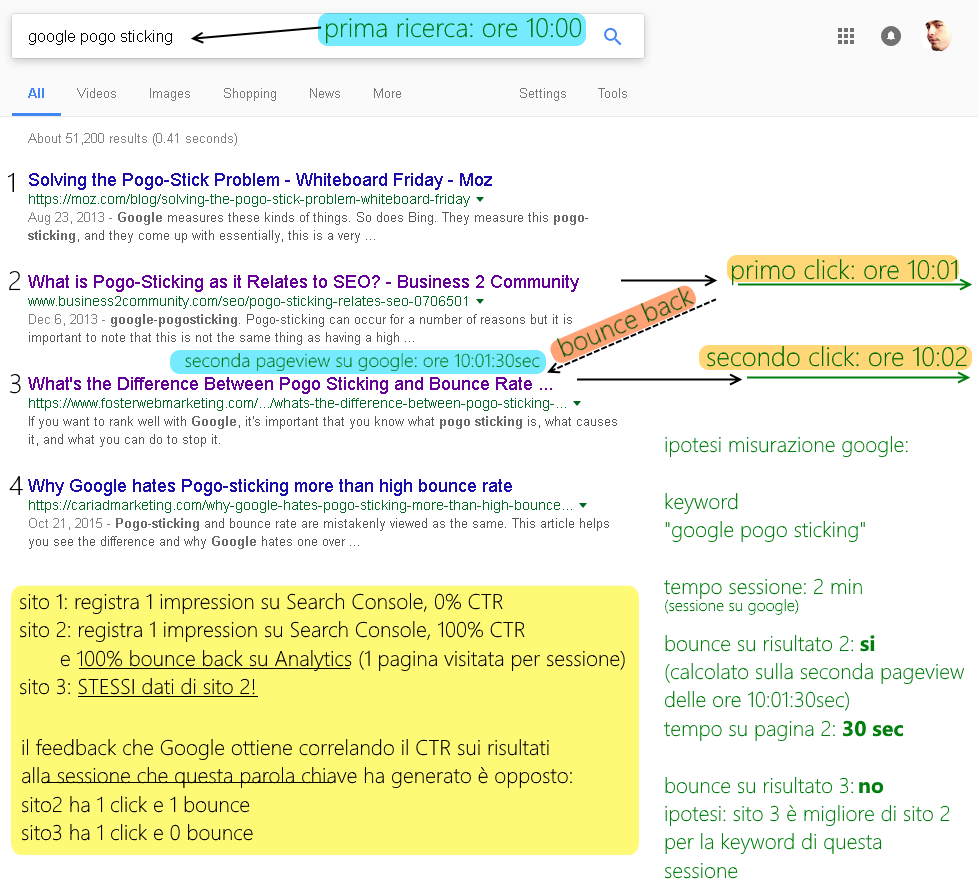
E il bounce back sui referral social, come lo consideri?
Come accade per il motore di ricerca possiamo ipotizzare che anche Facebook abbia modi per misurare i click sugli articoli che non hanno portato ad una lettura effettiva (bounce cattivo). Probabilmente loro riescono a misurarlo ancora meglio di Google visto che la modalità con cui gli utenti usano Facebook è assidua (con sessioni che durano ore e ore). In ogni caso, il bounce back sui referral social non impatta direttamente sul bounce della ricerca organica, ma i due dati sono correlati: se il tuo articolo è scritto proprio male, o il tuo sito fa proprio schifo… probabilmente avrai due bounce back ugualmente alti.
Il bounce back è taroccabile: quindi è una metrica inutile?
non proprio. Il bouce back è una metrica di grande valore, ma il suo significato è ambiguo. Lanciando un evento sul timeout forzi il ricalcolo del bounce per tutte quelle sessioni che sarebbero rimaste a 100% di bounce back anche nei casi in cui il lettore ha letto per intero il nostro articolo. Più è alto il valore di questo timeout e più sarà significativo dal punto di vista di un corretto calcolo del tempo di lettura.
Ti fidi di Google Trends? Io no, e ti spiego perché
Riassunto se hai poco tempo: Google Trends fornisce dati campionati, dai quali si possono fare tante correlazioni e coi quali ci si può divertire molto, ma per analisi serie lo evito.
su Trends i dati sono troppo raggruppati per essere precisi
I dati di Trends sono campionati, manipolati al fine di vendere maggiore pubblicità sulle piattaforme di Google (* mia ipotesi) e inoltre “clusterizzati” cioè riprendono termini veramente digitati dalle persone ma anche termini “ricondotti”, cioè raggruppati per poterne dare una traccia visibile a grafico. Considerate che circa il 15% delle parole chiave che riceve Google ogni giorno, non sono mai state richieste negli anni precedenti (es. errori di battitura, diverso ordine di stesse parole ecc.) un semplice errore di raggruppamento per le parole comporta variazioni anche significative nei grafici di Trend… i quali per di più non forniscono indicazioni numeriche reali (dalle quali sarebbe possibile fare raffronti e stabilire quantomeno il margine d’errore necessario alle analisi quantitative) ma sono sempre ricondotti ad una scala virtuale da 0 a 100.
come fanno le persone a cercare qualcosa
Il modo in cui le persone cercano tra l’altro è ancora oggetto di studio ed è tutt’ora un piccolo mistero dato che risente in primo luogo del livello di cultura di ognuno, oltre che della singola “voglia di cercare” di ogni sessione di ricerca. Una persona che si sta informando su un certo argomento non compie mai una sola ricerca, bensì un grappolo di ricerche, spesso frammentate. Per esempio se cerco “tumore” e tra i risultati delle ricerche vedo un risultato che riguarda i “tumori al seno”, posso cliccare su quel risultato e la mia ricerca si conclude, senza che google possa rilevare nei dati di Trends (che riguardano le sole parole chiave digitate) il fatto che il mio interesse reale non riguardasse il tema generico dei tumori.
Per complicare le cose, va considerato che durante il periodo di “ricerca” le persone chiedono spesso anche ai propri contatti “umani” per poi effettuare nuove ricerche, stavolta più mirate (anche in questo caso, i suggerimenti dei contatti umani creano una specie di “buco” nei dati che Trends può registrare).
Il modo in cui le persone cercano è inoltre soggetto ad un costante apprendimento da parte della popolazione, che utilizza il motore di ricerca in modo sempre diverso ogni anno che passa. Per esempio cercando “tumore” sembra che l’interesse nei tumori degli ultimi 10 anni sia in crescita “blanda” (+15/20% in 10 anni). Cercando però anche “tumore al seno” notiamo che questa ricerca sembra essere in crescita di oltre il 30%. Questo avviene perché le persone sono sempre meno interessate nei termini generici, e sempre più interessate in chiavi ultra precise, per esempio “tumore al seno menopausa diagnosi” delle quali non abbiamo garanzia che vengano prese in considerazione dall’algoritmo che filtra le ricerche per andare a creare il grafico dei dati offerto da Trends.
Inoltre, non è possibile cercare qualcosa della quale non si conosce l’esistenza, se non utilizzando parole molto generiche, e spesso mai raggruppate all’interno delle ricerche di trends. (a riguardo uno studio interessante è quello di Eli Parisier, che ha teorizzato una “filter bubble” cioè uno stato in cui viviamo e nel quale non riusciamo a sapere dell’esistenza di cose troppo lontane dal nostro comprendere).
in pratica?
In pratica è come dire che i dati presenti su Trends riguardano solo le ricerche di persone che sono a conoscenza di un certo soggetto e che necessitano approfondimenti. Per questo motivo spesso i dati di trends risentono di “onde mediatiche” causate da fonti di informazione esterne a Google (vedi ad esempio i picchi in occasione del mese di ottobre per le varie “giornate” indette per parlare di determinate patologie).
La stessa Google che qualche anno fa aveva lanciato in pompa magna il progetto “Google flu” prometteva di prevedere i luoghi nei quali sarebbero arrivate le prossime ondate di febbre/influenza/malaria ha dovuto accantonare il progetto, non potendo realmente prevedere e neppure analizzare gran che (oggi il progetto è in attesa di “contributi scientifici” e accetta iscrizioni tramite questo modulo )
quando usare Trends e soprattutto quando non usarlo
Google Trends è uno strumento commerciale reso molto didattico per massimizzarne l’utilizzo. In questa semplificazione si perde tutta la parte numerica delle informazioni; risultato: viene usato per raccontare storie che non esistono. Ha senso quindi utilizzarlo giusto per individuare “andamenti” (come suggerisce anche il nome), ma non può essere preso come metro di riferimento per fare scelte di business mirate, o peggio analisi scientifiche.
quand’è che un dato può essere considerato affidabile?
- Per prima cosa serve che esista un dato, sembra banale vero? Eppure Google Trends non fornisce alcun indice sui volumi delle ricerche. Tutti i grafici sono trasformati su scala 0-100, e non vengono mostrati mai i volumi di ricerca reale (che invece sono presenti all’interno di strumenti a pagamento come Google Adwords).
- Serve che per ogni dato campionato sia specificato il margine di errore minimo e massimo (anche questo non viene fornito da Trends).
- I dati devono essere correlati alla loro rilevazione, la quale deve avere link specifici (ad esempio in ogni pubblicazione scientifica nella quale siano presenti dei trial vengono indicati i giorni dell’esperimento, il numero di partecipanti, le loro caratteristiche fisiche ecc.)
quindi per fare analisi che dati utilizzi?
Insomma non affido una ricerca “seria” nelle mani dei dati di Google Trends.
Quando svolgo analisi per i clienti (nel 2016 ne ho fatte per IEO e CardiologicoMonzino) preferisco analizzare dati reali e dei quali posso ricostruire la storia di navigazione: le ricerche che arrivano sui vari siti, per analizzare le quali uso Search Console anch’esso offerto da Google, e tuttavia molto più “mirato” rispetto a Trends perchè contiene solo i dati del singolo sito internet. Purtroppo Search Console non permette rapidi raffronti tra dati di più siti, per i quali serve Google Data Studio.