* Quando scrivi un articolo su internet è importante non usare parole troppo comuni, la gente e i motori di ricerca potrebbero pensare che non hai niente di nuovo da dire.
(consiglio gentile offerto da NerdGranny)
Si parla di web semantico senza costruirlo, da anni. Per ora gli unici strumenti concreti sono i temi e plugin RDFa di WordPress e dopo 5 anni dal boom di WordPress (forse anche dato dalla iniziale propensione di Google per la semantica applicata bene) in generale nessuno si sta preoccupando di costruire strumenti tecnici amichevoli (ad esempio WordPress è amichevole) per la gestione dei contenuti che ci possano aiutare a duellare con cosa succederà domani sul web, visto che stiamo vendendo così bene su AdWords (anche se aimè costicchia) molti si sono adagiati sui soldi. Questa qui sotto è una mappa concettuale interessante che collega i tormentoni del web alle tecnologie relative che stiamo usando negli anni per accedere alle informazioni.

“WEB 4.0?! EEE”H MA CHE CAZZO DICI?”
Questo intervento maleducato vi è offerto da SEO ROBOT
A seconda della tecnologia che i web content editor usano, le informazioni che vanno a mettere disponibili sulla rete possono essere trovate con i motori di ricerca o con i social networks o coi tool di aggregazione semantica di ricerche legate ai contenuti (come diceva Giacomo Pelagatti al SEOCamp2010, anche Youtube è un search media).
I collegamenti tra le basi di dati
Sul web tutto quello che noi umani ancora non vediamo, è il modo in cui i dati si mescolano e vengono prelevati dalle macchine che poi usiamo per cercare altri dati. Questo tra l’altro è anche uno dei motivi per cui mi sono interessato di SEO, cioè la branca pratica di applicazione di concetti complessi riguardanti il ritrovamento di informazioni sulla rete. Richiamo dalla memoria la presentazione di Christian Morbidoni a FammiSapere2010 per parlare un po’ del livello di interconnessione tra le basi di dati, che si lega al significato che ogni base di dati porta con se.

Da queste due slides piene di freccie dai significati mutevoli e poco didattici si capisce fondamentalmente una cosa: che sul web il livello di complessità aumenta. La difficoltà nella nostra percezione di cosa è informazione e cosa è rumore aumenta solo se usiamo lo stesso metro di giudizio per desumere informazioni tra due insiemi di dati che a causa della crescente complessità diventano disomogenei tra loro. Lo stato del web attuale che identifica l’aumentare della complessità come parametro di valutazione della rete stessa si potrebbe anche legare ad un altro metro di giudizio soggettivo, la produttività nella raccolta di informazioni:

Da questa vecchia slide di Nova Spivack capiamo il suo punto di vista sulla produttività della “ricerca tramite motori di ricerca tradizionali” che cala all’aumentare della complessità di informazioni non strutturate presenti sul web, e che invece aumenta nel momento in cui il motore di ricerca inizia a “percepire” anche concetti semantici. Sappiamo ormai che Google con la semantica va a braccetto da anni, anche nel 2008 quando Nova Spivack ha fatto il suo speech (qui un bel commento di Jesse Farmer). Per il momento questo declino della produttività relativo alle keywords sui motori di ricerca non mi sembra sia ancora avvenuto, tuttavia è un futuro plausibile. L’unico che mi viene in mente è Cesarino Morellato, quando al SEOCamp2010 ci diceva (qui lo streaming) il suo punto di vista molto simile riguardo al declino delle parole chiave (senza dirmi però dove andrò a lavorare 😉 ).
il futuro del SEO è già un po’ qui.
Il mio punto di vista, è abbastanza chiaro e meta-comunicato nella presenza stessa di questo post: credo sia importante dare risalto alla trasparenza nel comunicare cose che sappiamo e dare i crediti pubblicamente, il motore di ricerca indicizza, le persone scelgono, i social network danno un contesto fornendo spesso link da persona a persona.
C’è ancora moltissima strada da fare anche solo per capire come taggare informazioni a livello macchina, quali plugin per WordPress usare magari (ad esempio WP-RFDa è interessante ma rompe il mio template). Più mi addentro nella ricerca del “senso” leggendo libri su linguistica, semantica e retorica e più mi sembra di tornare a Torino, al centro del crollo demografico quando facevo i corsi di doppiaggio da Ivo, mentre trovavo una città enorme, placida e vuota in cui tutta la storia del regno d’Italia era già stata scritta e non c’era nessuno per la strada con cui parlarne. Già che ci sono nel titolo ho dato anche l’addio alla prima pagina, visto che da una settimana Google si è accorto che questo sito non è più quinta risorsa in italia per chi sta cercando SEO, e quindi anche per me è tempo di evolvere.
Esperimenti di integrazione di RDF

Come è chiaro che gli infografici avranno una parte essenziale nella divulgazione di dati complessi, così questo disegno che ho messo ci spiega che in realtà qualcuno a fare un web semantico ci sta provando davvero: metto qui sotto qualche link a progetti scaricabili per integrazioni di semantiche a database di contenuti (cioè oggi WordPress e Drupal)
- un bel video didattico sulla semantica applicata al web
- Bendiken su github
- versione semantica di Drupal
- modulo RDF per Drupal
- classi ARC integrabili con un plugin per WordPress
- chi usa ubiquity per estrarre dati da pagine internet pubblicate senza uscire da Firefox
- e anche workshops di RDFa
- e chi pensa a integrare RDFa sul tinyMCE e chi lo ha già fatto per eventi e vcard
- ovviamente linko anche il palloso sito del w3 già che ci sono
- c’è chi fa intregrazioni con twitter via SPARQL e pensa a come linkare contesti differenti
- c’è chi studia modelli tecnologici per pubblicare meta-leggi
- e chi estrae dati semantici da community che rilasciano open data
- c’è chi mette assieme delle API per interfacciarsi a Linked Open Data
Ambiti corporate:
- CMS commerciali basati su Linked Data
- Liferay si mette a integrare RDF
Il riassuntone per chi non ha voglia di leggere tutto il post
Nell’eterna lotta tra piccoli siti web e mega siti commerciali, solo WP e Drupal aiutano i non-tecno-maniaci, e anche se si adoperano per metterci nelle condizioni di pubblicare semanticamente, la sensazione è che tanti piccoli siti web cerchino di dare significato alla loro esistenza, permettendo l’aggregazione pubblica di collegamenti ed esistenza di rapporti tra un sito e l’altro. Un utente Facebook che decidesse di rendere pubbliche questo genere di informazioni sui suoi rapporti col mondo poteva farlo anche 2 anni fa, senza problemi, senza menate tecnologiche, anche se firmando per la cessione di ogni suo contenuto inglobato dal social network.
Ovviamente farselo in casa ha un sapore migliore. Tra l’altro anche la BBC si adopera per entrare in modalità semantiche.
Fonti usate per questo articolo
- Google Alerts con avviso RSS su keyword “WordPress RDF”
- Slides a Fammi Sapere di Christian Morbidoni
- diagramma originale di Linked Open Data
- diagramma coi link ai vari database
- Is Keyword Search About To Hit Its Breaking Point? – presentazione di Nova Spivack
- L’infografico sulla semantica è di Benjamin Nowack
- blog di lavoro del progetto LOCAH
- la versione faccettizzata di wikipedia
- un esempio di “faccettizazione” di un ecommerce
Aggiornamenti 2014
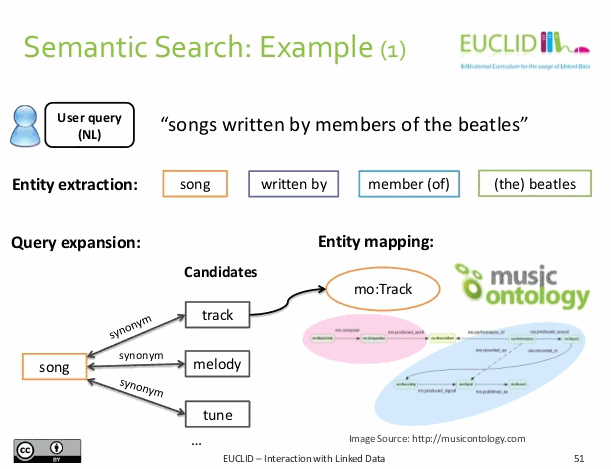
- un bellissimo esempio di Linked Open Data e semantica applicate nel concreto
- ottimo riassunto sull’utilizzo dei tag H1-H6 in contesto HTML5
Knowledge graph e vault
Dopo Knowledge graph, nel quale google mostra in SERP alcuni dati strutturati presi principalmente da Freebase e Wikipedia, ora arriva Knowledge Vault (qui un articolo con qualche approfondimento) che dovrebbe essere in grado di dare risposte alle domande degli utenti con un certo grado di approssimazione (quindi darà anche risposte errate).
Ciao Simone, desidererei chiederti delle informazioni. In realtà io non sono molto esperto del mondo web, in passato ho studiato il Java, database relazionali e linguaggi euristici lisp derivati come il Clips-Jclips per la costruzione dei stistemi esperti. Il web semantico è certo un’idea brillante, una simile struttura faciliterebbe e velocizzerebbe molto la navigazione in internet e l’accesso ai contenuti, ma da quanto ho capito per motivi tecnici bisognerà aspettare ancora un pò.
Nel frattempo mi domandavo se fosse utile, soprattutto per siti vasti, molto complessi e articolati, ricchi di contenuti e servizi non sempre facilmente e agevolmente accessibili, implementare nell’applicazine web un sistema esperto in grado di gestire passo passo la navigazione da parte dell’utente, attraverso ad esempio una piccola finestra di dialogo che comparirebbe in ogni ipertesto, che gli consentirebbe, attraveso comunicazione con linguaggio naturale, di porre domande su ciò che desidera cercare in termini di contenuti e servizi, rendendo così notevolmente veloce e facile la consultazione e l’utilizzo del sito. Ad ogni richiesta il sistema esperto gestirebbe automaticamente la scelta e l’invio dell’ipertesto oppure darebbe indicazioni sul percorso di link da cliccare per accedere ai contenuti desiderati.
E’ solo un’idea, qui espressa in forma appena abbozzata…. Se vuoi dammi un tuo parere.
Ciao.
ciao Guido! difficile a dirsi in poche righe. In linea di massima ai motori di ricerca piace molto qualsiasi contenuto testuale che riescano a “spiderizzare” in poco tempo e con poco margine di errore. Sanno già riempire moduli semplici, azionare javascript e flash… ma non credo potrebbero fare richieste “vocali” o in linguaggio naturale per il momento. In italia abbiamo molti siti che traggono forte vantaggio da implementazioni di sistemi esperti per la categorizzazione e strutturazione di grandi moli di dati (ad esempio liquida.it è un aggregatore abbastanza intelligente, anche il sito del sole24ore monta varie tecnologie semantiche). Quindi riassumendo si, nuovi servizi utili agli utenti potrebbero in futuro essere utili anche per i motori di ricerca, purtroppo i costi di sviluppo per questo genere di piattaforme sono elevatissimi per il momento! ciao! simo